Don't worry! The contents here will appear on the published page.
AI Still Fails One-Third of Real Accounting Tasks
Woosung Chun
CFO, DualEntry
.jpg)
Woosung Chun
CFO, DualEntry
Woosung Chun is the CFO of DualEntry with experience in corporate finance, accounting, strategy, and acquisitions. He previously grew from scratch and led the M&A and Finance teams at Benitago, where he completed more than 12 acquisitions in 2 years. He graduated with a BS from NYU Stern. At DualEntry, Woosung writes about AI in accounting, revenue recognition, foreign currency accounting, hedge accounting, and ERP modernization for finance teams navigating complex, multi-entity environments.
Learn about our editorial policies.
Last updated
March 25, 2026
Reviewed by
Do San (Justin) Myung

Do San (Justin) Myung
Expert Accountant & Former Consulting CFO | DualEntry
Justin (Do San Myung) is Expert Accountant at DualEntry with 20+ years of hands-on experience managing general ledgers, financial close processes, and ERP implementations for mid-market and enterprise companies. As a former Consulting CFO and Controller, he has personally overseen month-end closes, SOX compliance programs, and multi-entity consolidations across technology, manufacturing, and services industries. Justin specializes in transforming manual accounting workflows into automated, AI-driven processes.
Learn about our editorial policies.

Summarize this article
A new benchmark designed to measure AI performance across real accounting workflows reveals a clear ceiling and it's lower than much of the current enterprise AI narrative suggests.
DualEntry Labs tested 19 AI models against 101 task-oriented accounting questions spanning transaction classification, journal entries, accounts payable, reconciliation, and more. These were not coding challenges, trivia questions, or abstract reasoning benchmarks.
They were the kinds of tasks accounting professionals perform daily, grounded in a provisioned chart of accounts and designed to reflect genuine operational work.
The top-performing model, Gemini 3.1 Pro, achieved an accuracy score of 66.0%. The lowest, GPT-4 and GPT-4-0613, scored just 19.8%.
No model exceeded 70%.
Every model failed at least one-third of the tasks it was given. In structured financial workflows, those gaps compound quickly - especially in reconciliation, reporting, and month-end close processes where errors cascade downstream.
That top-line number deserves context. In software engineering, a 66% pass rate on unit tests would halt a deployment. In medicine, it would trigger a review.
In finance, 66% accuracy isn't automation. It's assisted drafting.
The results don't suggest AI has no role in accounting. They suggest that autonomy in financial workflows remains premature - and that reliability still depends on system-level controls and human oversight.
Accuracy Ranking of 19 AI Models on Accounting Workflows
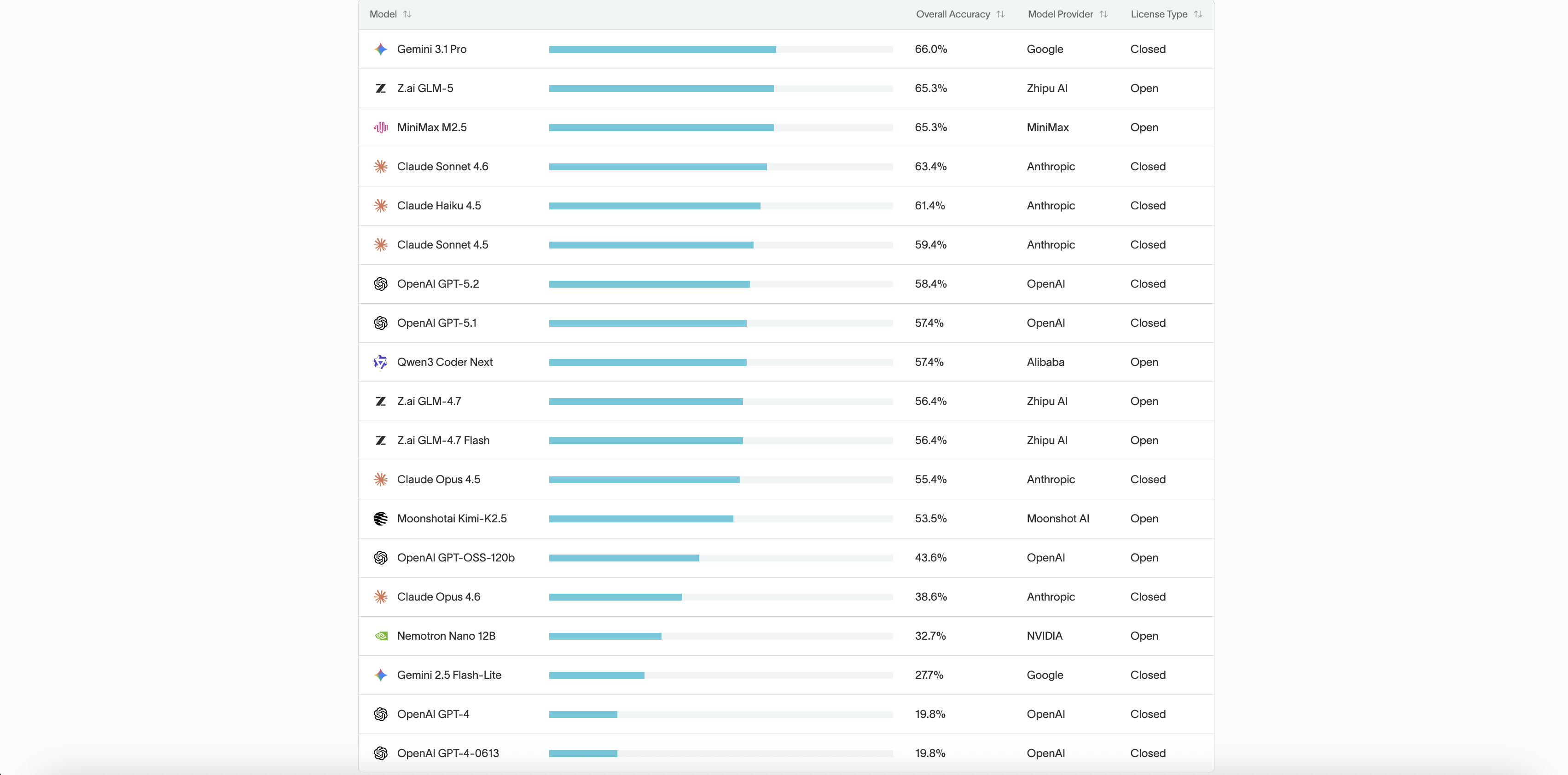
Source: DualEntry Labs: 2026 Accounting AI Benchmark.
What Was Tested
The benchmark comprised 101 domain-specific questions divided across eight core accounting workflow categories:
- Transaction Classification (13)
- Journal Entry Creation (13)
- Accounts Payable (13)
- Accounts Receivable (12)
- Bank Reconciliation (12)
- Financial Reporting (13)
- Month-End Close (12)
- AI Accounting Knowledge (13)
Each question was designed against a provisioned chart of accounts, with minimal contextual information provided. Prompts were designed to provide only the information necessary for each task to function, without embedding excessive contextual guidance. Every question was task-oriented: classify this transaction, create this journal entry, reconcile this statement, generate this report.
Models were run in isolated environments with no connection to live accounting systems or real financial data. No model carried forward context or memory between tasks. This was intended to isolate each model's standalone performance against a consistent, controlled set of inputs.
Grading was deterministic. Every response was scored as binary correct or incorrect, with no partial credit. The benchmark allowed multiple runs per model, enabling the calculation of three key metrics: accuracy across the full question set, standard deviation per workflow category, and a difficulty tier classification for each question based on aggregate model performance.
The benchmark prioritized operational relevance over breadth. It was designed not to measure what a model can say - but how reliably it can execute structured accounting work.
The Performance Spectrum
The accuracy range across all 19 models tested was substantial - from 66.0% at the top to 19.8% at the bottom. That material performance spread reveals not just differences in model capability, but unevenness in how current AI systems handle structured financial workflows.
Gemini 3.1 Pro led at 66.0%, followed closely by GLM-5 and MiniMax M2.5 at 65.3%. A cluster of models landed between 55% and 63%, suggesting a competitive but tightly bounded middle tier where incremental architectural or training differences produced modest gains. Below that, a second grouping settled around 53–58%, still completing more than half of tasks correctly but showing meaningful variance across workflow categories.
The drop-off after those tiers was significant. Several models fell below the 50% mark, completing fewer than half of the tasks correctly. At the bottom of the range, GPT-4 and GPT-4-0613 scored 19.8%, well below the top-tier performers.
It is worth noting that a low score does not necessarily indicate a fundamentally incapable model. Benchmark design, prompt sensitivity, and task framing all influence results. But the consistency of reliability gaps across the full field - 19 models, none exceeding 70% —-points to structural limitations rather than isolated outliers.
No model demonstrated consistent, end-to-end reliability across all eight workflow domains. Even the strongest performers showed variance across categories, excelling in some areas while underperforming in others.
Why Accounting Is Hard for LLMs
Most AI benchmarks test a model's ability to generate plausible language. Accounting demands something fundamentally different structured precision within a system of interdependent rules.
Every journal entry must balance. Every transaction must be classified against a defined chart of accounts. Every reconciliation must resolve to zero. These are not tasks where approximate answers carry partial value. They are binary: the entry balances or it doesn’t, the account maps correctly or it doesn’t, the reconciliation resolves or it fails.
Beyond accuracy on individual tasks, accounting workflows require persistent state - the ability to carry forward balances, recognize prior entries, and maintain consistency across related actions. They require contextual memory, so that a transaction recorded in accounts payable is correctly reflected downstream in financial reporting and month-end close. They require deterministic output, where the same inputs reliably produce the same results. And they require audit traceability - every figure must be explainable and reversible.
Large language models are probabilistic by design, generating the most likely next token rather than a formally validated ledger entry. That probabilistic foundation can create friction in environments where deterministic precision is required. A misclassified transaction does not remain isolated - it can propagate downstream, affecting balances, reporting, and the close process.
A 34% failure rate in journal entry or reconciliation workflows is not a marginal gap, it materially limits autonomous use.
What This Means for Enterprise AI
The benchmark results do not argue against AI in accounting. They argue for a more precise understanding of where AI adds value and where its limitations must be managed.
Large language models are, at their core, drafting engines. They excel at generating structured text, suggesting classifications, and accelerating repetitive cognitive tasks. In accounting, that makes them useful for first-pass transaction coding, preliminary journal entry creation, and surface-level anomaly detection. These are real, measurable productivity gains.
But accounting systems do not run on drafts. They run on validated records entries that balance, classifications that map to a defined chart of accounts, reconciliations that resolve to zero, and reports that withstand audit scrutiny. The distance between a plausible draft and a validated record is precisely where operational complexity lives.
Reliability matters more than fluency. A model that generates a convincing but incorrect journal entry creates downstream reconciliation and reporting challenges. In financial workflows, confidence without accuracy can be more difficult to detect than an obvious gap, because it embeds errors that propagate through the reporting chain.
“Large language models are powerful drafting tools. But finance doesn't run on drafts it runs on validated records.”
Autonomy in financial workflows requires system-level grounding AI operating within structured systems of record, bounded by validation rules, reconciliation logic, and formal control frameworks. Without that infrastructure, even the highest-performing model in this benchmark remains a drafting tool that requires human review.
The question for enterprise finance is not whether to adopt AI. It is whether the systems surrounding that AI are built to manage what it gets wrong.
Methodology Transparency
The benchmark was designed as a domain-specific, task-oriented evaluation of AI performance across real accounting workflows. All 101 questions were built against a provisioned chart of accounts and divided across eight core workflow categories reflecting the operational scope of professional accounting.
Each of the 19 models was tested in an isolated environment with no connection to live financial systems and no shared context between runs. Grading was deterministic and binary — every response was scored as correct or incorrect, with no partial credit and no subjective evaluation.
Multiple runs were permitted per model to calculate overall accuracy, standard deviation per workflow category, and difficulty tier classification per question. The structure prioritized reproducibility and operational relevance over single-pass benchmark performance.
Full methodology details and complete model comparisons are available here. https://www.dualentry.com/accounting-ai-benchmark
Technical Review: Ignacio Brasca, Staff Engineer — DualEntry
See the full power of DualEntry in 30 minutes
Woosung Chun
CFO, DualEntry
Woosung Chun is the CFO of DualEntry with experience in corporate finance, accounting, strategy, and acquisitions. He previously grew from scratch and led the M&A and Finance teams at Benitago, where he completed more than 12 acquisitions in 2 years. He graduated with a BS from NYU Stern. At DualEntry, Woosung writes about AI in accounting, revenue recognition, foreign currency accounting, hedge accounting, and ERP modernization for finance teams navigating complex, multi-entity environments.